Embodied AI Reading Notes (@EmbodiedAIRead)
2026-01-06 | ❤️ 95 | 🔁 19
Large Video Planner Enables Generalizable Robot Control
Project: https://www.boyuan.space/large-video-planner/ Paper: https://arxiv.org/abs/2512.15840 Code: https://github.com/buoyancy99/large-video-planner/tree/main
This paper explores a new way to use video generation model to learn robot policy: use finetuned video generation model to produce zero-shot video plans for novel scenes and tasks, and then post-process to extract executable robot actions.
-
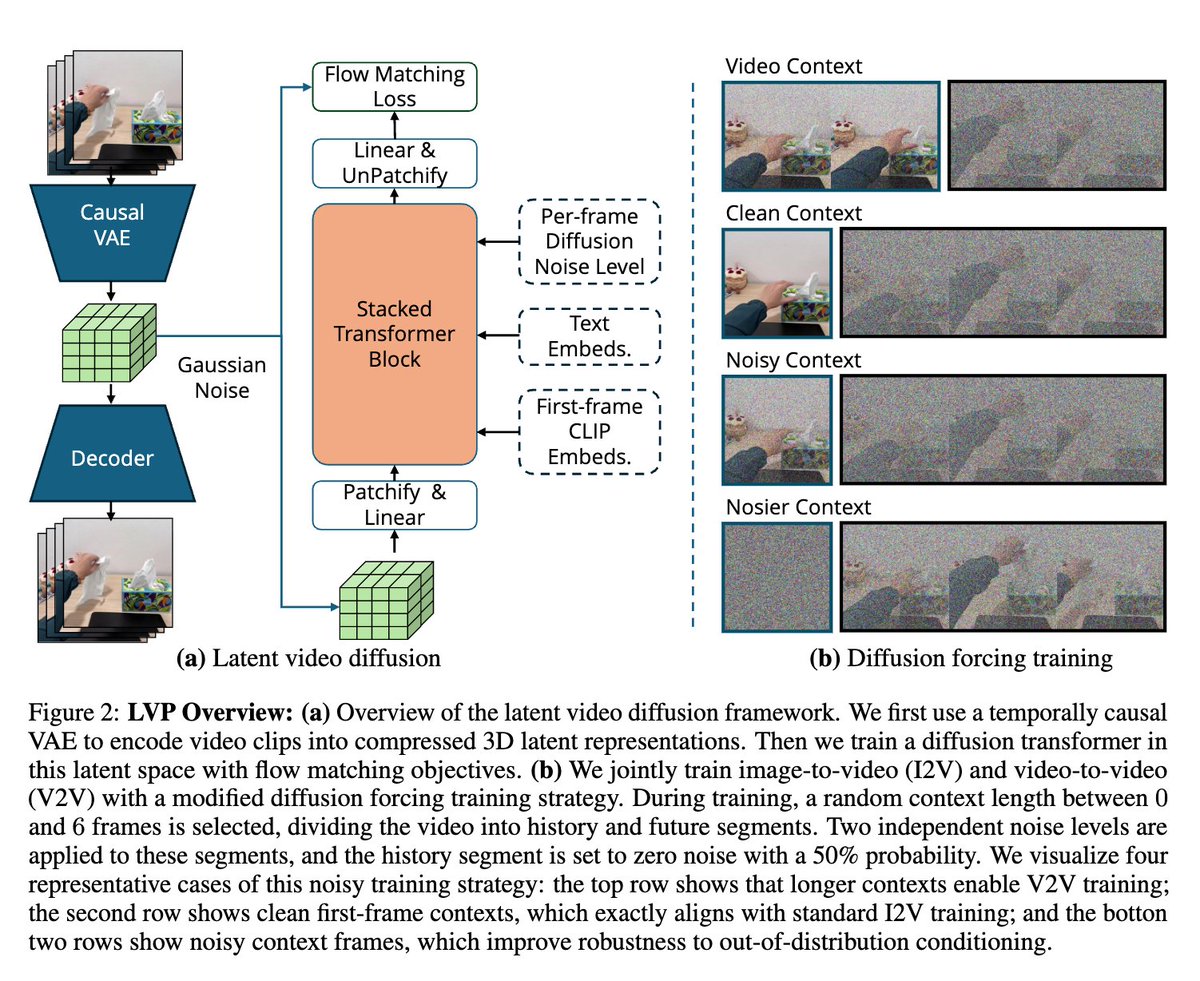
Conditional video generation model: given text instructions and initial observation frame(s), generate video plans. Carefully finetuned with large-scale internet and robot videos, the model use History Guidance and Diffusion Forcing to enhance temporal coherence and causal consistency in generation.
-
The paper also open-source the curated diverse and high-quality 1.4M clips of human/robots interacting with objects they used for training.
-
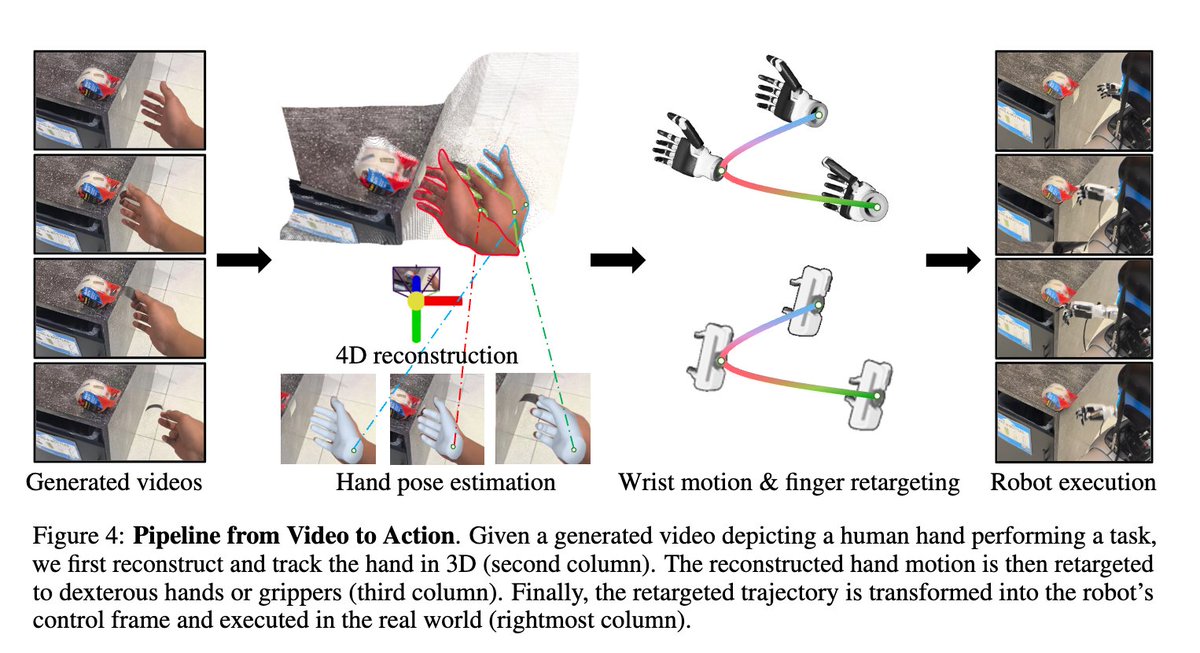
From video to action: generated video → hand pose estimation → wrist motion & finger retargeting → robot execution.
-
The authors show the generated policy can run on a G1 with dexterous hand to do grasping etc in real world.
-
Limitation: the video generation takes minutes making the policy open-loop and real-time deployment on robots intractable.
🔗 원본 링크
- https://www.boyuan.space/large-video-planner/
- https://arxiv.org/abs/2512.15840
- https://github.com/buoyancy99/large-video-planner/tree/main
미디어
🔗 Related
Auto-generated - needs manual review