Chris Paxton (@chris_j_paxton)
2024-10-09 | ❤️ 212 | 🔁 38
How do we represent knowledge for the next generation of in-home robots?
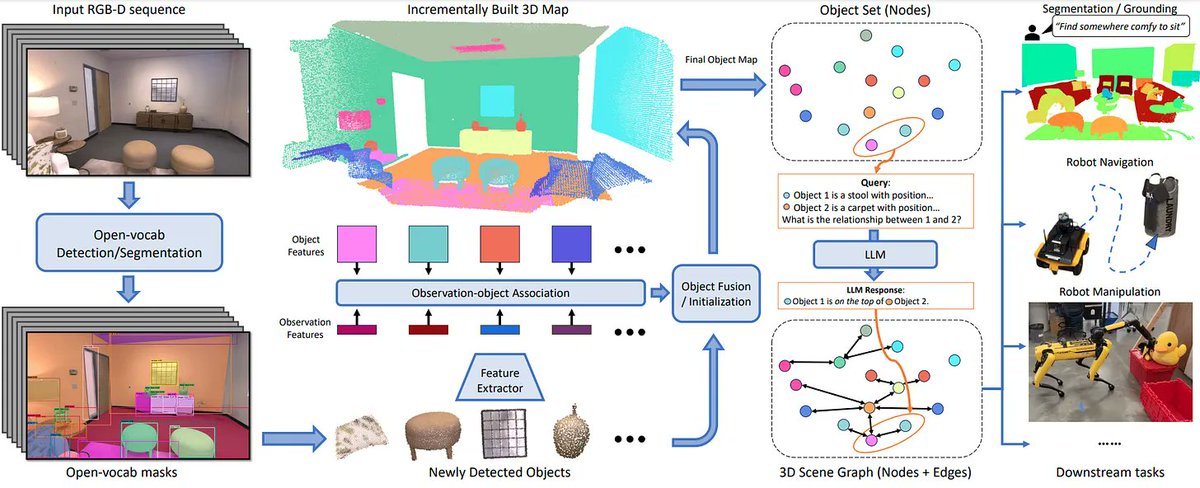
We want generally useful robots which can execute multi-step, open-vocabulary queries. This means that I should be able to tell my robot something like “check to see if the dog has enough food” or “see if the water on the stove is boiling.” That means a robot that has rich knowledge of the world: where objects are, what it can do, etc.
This is not something end-to-end models are doing yet. Instead, the way I see it, there are three main options:
- Use something like retrieval-augmented generation and a large vision-language model to make decisions
- Generate some rich 3d feature-based representation
- Build complex open-vocabulary scene graphs
Short review of what’s happening in this space right now →
미디어