rsasaki0109 (@rsasaki0109)
2025-05-04 | ❤️ 157 | 🔁 28
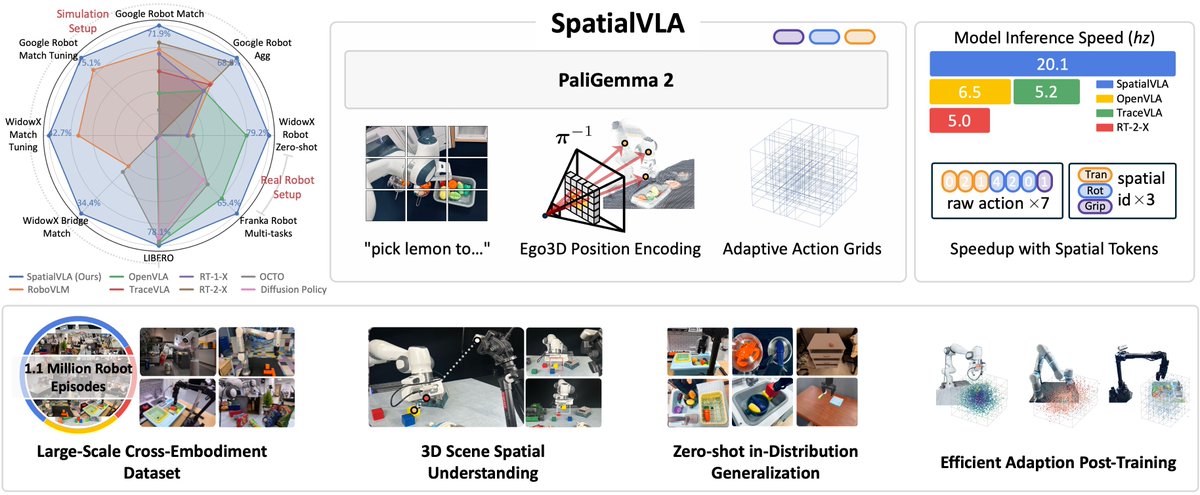
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models (RSS 2025) https://github.com/SpatialVLA/SpatialVLA A spatial-enhanced vision-language-action model trained on 1.1 Million real robot episodes. 🤗 purely huggingFace-based, concise code with efficient performance. https://x.com/rsasaki0109/status/1919158640247968240/photo/1
🔗 원본 링크
- https://github.com/SpatialVLA/SpatialVLA
- https://x.com/rsasaki0109/status/1919158640247968240/photo/1
미디어
🔗 Related
Auto-generated - needs manual review
Tags
domain-robotics domain-ai-ml domain-dev-tools domain-visionos