机器之心 JIQIZHIXIN (@jiqizhixin)
2025-11-06 | ❤️ 133 | 🔁 14
UniLIP: a unified framework extending CLIP beyond understanding to multimodal generation and editing.
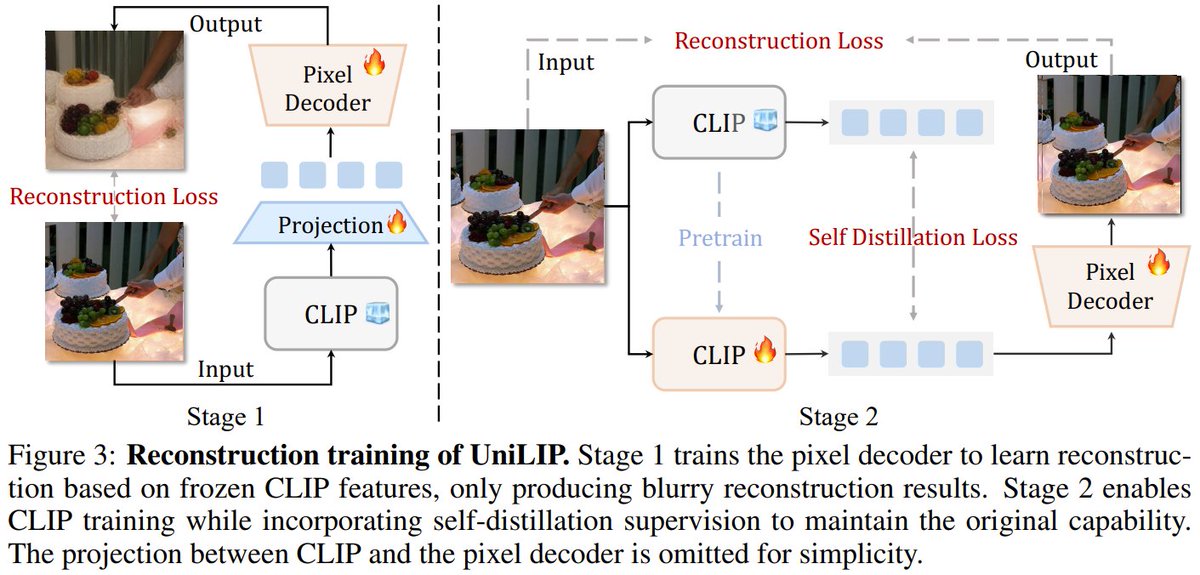
While CLIP excels at perception, it lacks reconstruction ability. UniLIP fixes this with a two-stage self-distillation scheme that adds high-fidelity reconstruction without sacrificing comprehension.
Built on the MetaQuery framework, UniLIP introduces a dual-condition architecture that fuses multimodal hidden states (for contextual richness) with learnable query embeddings (for MLLM-style reasoning).
With only 1B–3B parameters, UniLIP outperforms larger unified models like BAGEL (7B) and Uniworld-V1 (12B), reaching 0.90 GenEval, 0.63 WISE, and 3.94 ImgEdit, showcasing CLIP’s evolution into a fully capable multimodal foundation for understanding, generation, and editing.
UniLiP: Adapting CLIP for Unified Multimodal Understanding, Generation and Editing
Peking, Alibaba, CASIA Paper: https://www.arxiv.org/abs/2507.23278 Code: https://github.com/nnnth/UniLIP Model: https://huggingface.co/kanashi6/UniLIP-3B
Our report: https://mp.weixin.qq.com/s/6PfDB53uY_u_8b6hBmE1Qg
📬 PapersAccepted by Jiqizhixin
🔗 원본 링크
- https://www.arxiv.org/abs/2507.23278
- https://github.com/nnnth/UniLIP
- https://huggingface.co/kanashi6/UniLIP-3B
- https://mp.weixin.qq.com/s/6PfDB53uY_u_8b6hBmE1Qg
미디어