Chris Paxton (@chris_j_paxton)
2024-05-28 | ❤️ 118 | 🔁 18
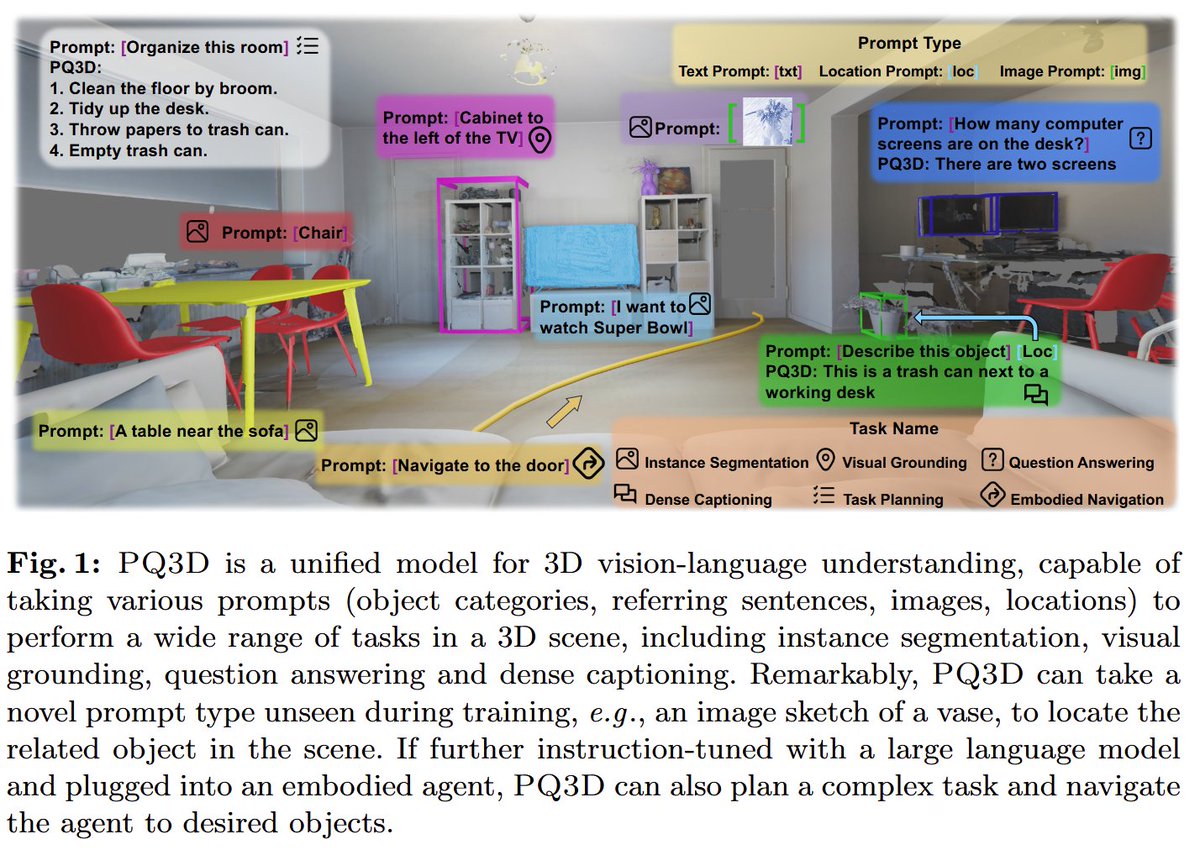
Unifying 3D Vision-Language Understanding via Promptable Queries
Understanding 3d scenes is a core challenge for embodied intelligence. PQ3D is trained to perform promptable queries on 3d vision-language tasks, getting SOTA on 10 different benchmarks. It does this by aligning multiple different representations for 3d information like images, voxels, and point clouds. What’s especially interesting is that it can handle many different important tasks simultaneously:
- instance segmentation
- object navigation
- open-vocabulary learning
- captioning
- question answering
미디어